毎週の歯科治療が一段落し, とうとう外に出る理由が一切なくなりました。
ホクソエムサポーターのKAZYです。
6畳の部屋に籠もり続けて健康を維持できるのか不安なこの頃。 運動不足も気になります。
ホクソエムのおじさんたちもきっと同じ悩みを抱えてることでしょう。
ところで最近は静止画を簡単に踊らせてやることができるらしいです。
referenceの動画の動きに合わせて、sourceの静止画をぐりぐり動かせるAI。
— 福田敦史 / Aillis CTO (@fukumimi014) December 13, 2020
Attention機構などを使い、referenceから抽出した動きの情報をsource画像に当てはめ、Discriminatorに真偽判定させるGANを主な機構として用いているとのこと。https://t.co/YdsiRi0Enp pic.twitter.com/7xQ8oohqyo
私は閃きました。
この技術を使ってホクソエムのおじさん達をグリグリ動かす。
そうすればおじさんの運動不足は解消される。
それにより, おじさんたちは気分が良くなる。
私は感謝されご褒美をたんまりもらえる。💰💰💰💰
素晴らしいシナリオです。
天才かもしれない。
今回のアウトプット(忙しい人用)




フリー素材です。
ご自由にお持ち帰りください。
今回使う技術の流れの雰囲気なお気持ち
ホクソエムブログって実はテックブログ的なものらしい(NOT ポエム置き場)。
なので今回使う技術のお気持ち程度の解説を記しておくことにする。
この技術が発表された論文の名はLiquid Warping GAN with Attention: A Unified Framework for Human Image Synthesis。
2020年のもの。
論文に載っていたFramework OverViewに私がちょびっとコメントを追加画像がこちら。
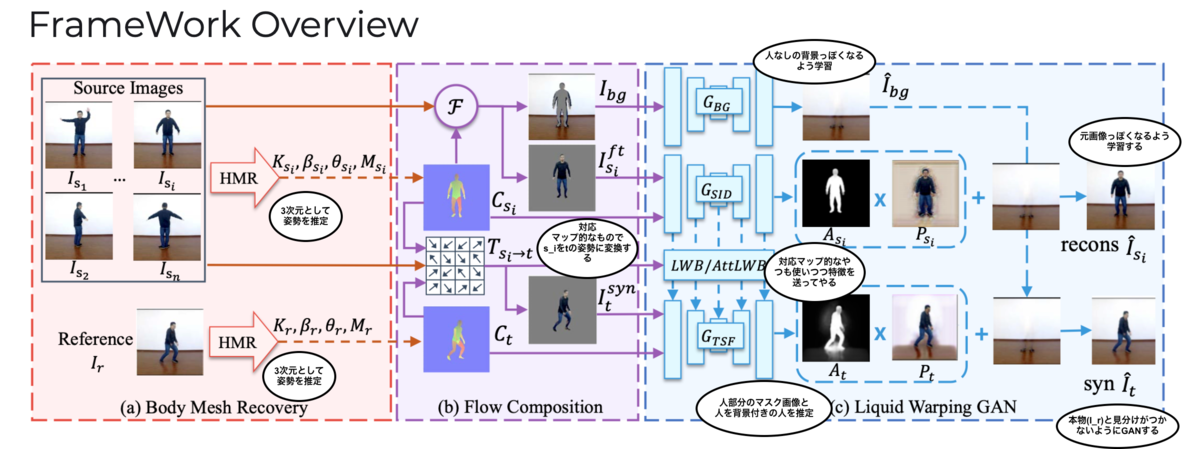
やってることはだいたいこんな感じだ。
やりたいことはSource Image をReference
のに姿勢にしたい。
なるべく自然な感じに。
それを実現するために考えられた流れは
2. 3次元メッシュを考慮した画像間の人物部位の対応マップ的な
3.
4. Convolutional Autoencoderライクな
5.
6.
上の流れでいい感じの結果を得るために
-
をあわせて学習する感じ (雑)。
あと一旦3Dメッシュにして3次元的な情報も考えているんだってところがポイントらしいです。
あとあとのところで人物を再構築するために使う特徴量を流し込んでやるところもポイントらしいです。
詳細は論文を読んでほしいです。
こちら↓のサイトに論文, コード, データセットなどなどが置いてあります。 www.impersonator.org
2021年02月現在はComing soonとなっていますが, いいのアプリケーションも開発するプロジェクトもあるようです。
おじさんの画像を集める
本題に戻ります。
おじさんたちの画像を集めます。
画像を募ったらなおじさん3名から画像を拝借できました(たぶんフリー素材)。




いい表情。
おじさんを動かす(その1)
この技術,嬉しいことにテストデータを動かしているノートブックが公開されているんです。
脳みそが🐵な私は画像だけ差し替えればなんか動くだろの精神でおじさん達を投入してみます。
ノートブックをしたに上から下に実行していきます。
トランプを踊らせている動画の設定のブロックにたどり着きました。
# This is a specific model name, and it will be used if you do not change it. This is the case of `trump` model_id = "donald_trump_2" # the source input information, here \" is escape character of double duote " src_path = "\"path?=/content/iPERCore/assets/samples/sources/donald_trump_2/00000.PNG,name?=donald_trump_2\"" ## the reference input information. There are three reference videos in this case. # here \" is escape character of double duote " # ref_path = "\"path?=/content/iPERCore/assets/samples/references/akun_1.mp4," \ # "name?=akun_2," \ # "pose_fc?=300\"" ref_path = "\"path?=/content/iPERCore/assets/samples/references/mabaoguo_short.mp4," \ "name?=mabaoguo_short," \ "pose_fc?=400\"" # ref_path = "\"path?=/content/iPERCore/assets/samples/references/akun_1.mp4," \ # "name?=akun_2," \ # "pose_fc?=300|" \ # "path?=/content/iPERCore/assets/samples/references/mabaoguo_short.mp4," \ # "name?=mabaoguo_short," \ # "pose_fc?=400\"" print(ref_path) !python -m iPERCore.services.run_imitator \ --gpu_ids $gpu_ids \ --num_source $num_source \ --image_size $image_size \ --output_dir $output_dir \ --model_id $model_id \ --cfg_path $cfg_path \ --src_path $src_path \ --ref_path $ref_path
あー, 完全に理解した。
ref_pathで動画, src_pathで画像を指定しているっぽいので, src_pathをおじさんに差し替えちゃえばいいんでしょう?
src_pathとmodel_idをおじさんに差し替えてみました。
# This is a specific model name, and it will be used if you do not change it. This is the case of `trump` model_id = "ossan01" # the source input information, here \" is escape character of double duote " src_path = "\"path?=/content/iPERCore/ossan-01.jpg,name?=ossan01\"" ## the reference input information. There are three reference videos in this case. # here \" is escape character of double duote " # ref_path = "\"path?=/content/iPERCore/assets/samples/references/akun_1.mp4," \ # "name?=akun_2," \ # "pose_fc?=300\"" ref_path = "\"path?=/content/iPERCore/assets/samples/references/mabaoguo_short.mp4," \ "name?=mabaoguo_short," \ "pose_fc?=400\"" # ref_path = "\"path?=/content/iPERCore/assets/samples/references/akun_1.mp4," \ # "name?=akun_2," \ # "pose_fc?=300|" \ # "path?=/content/iPERCore/assets/samples/references/mabaoguo_short.mp4," \ # "name?=mabaoguo_short," \ # "pose_fc?=400\"" print(ref_path) !python -m iPERCore.services.run_imitator \ --gpu_ids $gpu_ids \ --num_source $num_source \ --image_size $image_size \ --output_dir $output_dir \ --model_id $model_id \ --cfg_path $cfg_path \ --src_path $src_path \ --ref_path $ref_path
あと, 一つ前のセルでnum_source = 2となっていますが, 今回はおじさん画像は1枚なのでnum_source = 1に修正しました。
そしてRun the trump caseのブロックを実行してみます。
待つこと数分。。。
----------------------MetaOutput---------------------- ossan01 imitates mabaoguo_short in ./results/primitives/ossan01/synthesis/imitations/ossan01-mabaoguo_short.mp4 ------------------------------------------------------ Step 3: running imitator done.
という表示がでました。 どうやら終わったようです。
おおおおおおおお!!!!! 動いたーーー!
おじさんがおじさんの動画と同じ動きをしております。
なにかの武術を完全にマスターしていますね。
素晴らしい。 強そう。
おじさんを運動せてみる(その2)
今度は別のおじさんを動かしてみましょう。
こちらのおじさん(多分ホクソエムの社長さん)。
先程はサンプルー動画でしたが動画もこちらが指定したものに差し替えてみましょう。
ref_pathを適当に拾ってきた動画に変更します。
あとおじさんも別のおじさんに変えてみます。
社長さんに変な動きをさせている背徳感が堪らない。。。
あと単純に普段していないであろう動きをしているおじさんが面白い。
おじさんを運動せてみる(その3)
調子に乗って最後は激しいダンスとかおじさんにさせてみようと思います。
踊るおじさんがよりリアルになってほしいので今回は正面と背面と2枚の画像を入力してみます。
GO!!!
いやぁ...お腹が痛い。。。
キレッキレじゃないですか。
たまにありえない動きしちゃうあたりが, 手法的にはマイナスなんでしょうがお笑い的には◎。
いやぁ 笑った笑った。
最後に
今回はLiquid Warping GAN with Attention: A Unified Framework for Human Image Synthesisという論文の手法を用いてホクソエムのおじさんの画像を動画と混ぜ合わせて動かしました。
実装がColaboratoryにアップロードされておりとても簡単に動かすことができました。
アウトプットを見るのがとにかく面白かったので, 皆様も身近な人で試してみてはいかがでしょうか。
おじさん達の運動不足を解消したので私はホクソエムからボーナス間違いなしですね 。💴💴💴💴💴