ホクソエムサポーターの白井です。学生時代は自然言語処理の研究をしていました。
「今年読んだ論文、面白かった5つ」というテーマで、自然言語処理(NLP)の論文を紹介します。 主にACL anthologyに公開されている論文から選んでいます。
- はじめに 今年のNLP界隈の概観
- 1. Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems
- 2. Errudite: Scalable, Reproducible, and Testable Error Analysis
- 3. Language Models as Knowledge Bases?
- 4. A Structural Probe for Finding Syntax in Word Representations
- 5. Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts
- おわりに
はじめに 今年のNLP界隈の概観
NLP界隈はELMoやBERTが提案されたことによって、多くのタスクが高い精度、人間のパフォーマンスに近い精度を達成できるようになりました。去年から、"BERTをfine tuningしてSOTA" という主張の論文が散見される状況であると個人的には感じています。
その一方で、このモデルは本当に人間と同等の能力を持っていると言っていいのか?モデルのパフォーマンスをどう解釈すべきか?というような、 モデルの 解釈性 について疑問を問いかける、あるいは、モデルそのものを 検証 する研究も多く発表されている印象を受けています。
同じ流れで、新しいデータや、既存のデータを拡張したデータの公開も常に盛んに行われています。 解釈性の話とも被る部分がありますが、今のモデルでは解けないようなタスクを提案し、データを公開することで、研究領域全体として高めていこうという流れを感じます。
今回は、このような研究の流れを踏まえ、検証系の論文をメインに紹介したいと思います。
1. Text Processing Like Humans Do: Visually Attacking and Shielding NLP Systems
NAACL2019
- arXiv https://arxiv.org/abs/1903.11508
- ACL anthology https://aclweb.org/anthology/papers/N/N19/N19-1165/
- github https://github.com/UKPLab/naacl2019-like-humans-visual-attacks
Adversarial attack、もしくはAdversarial Perturbation (敵対的摂動) はComputer Vision (CV) 分野のパンダの例で有名な、ノイズを加えることで分類器に誤識別させるものです。

From https://openai.com/blog/adversarial-example-research/
この論文では、画像ではなく、文字のゆらぎを機械が扱うにはどうすればよいか検証しています。 adversarial attackがNLPにおいて重要である例のひとつとしてkaggleのtoxic-comment-classification-challengeをあげています。
toxic comment classificationは、wikipedia上のコメントが有害であるかどうかを分類するタスクです。このタスクの難しい点として、SNSなどweb上のコメントでは、有害な単語表現は、文字を置き換えて難読にしていることが挙げられます。

From https://www.aclweb.org/anthology/N19-1165/
上記例では、idiot という有害な単語を idiøţ と表記しています。
このように、人が見た目では読める単語 (idiøţ) も、分類器は文字コードでエンコードした分散表現を用いるため、idiøţ が idiot だと認識できません。これが、人間と機械の間にあるボトルネックです。
そこで、本論文では、文字を画像として扱う敵対機構を提案しています。
具体的には、以下の内容が述べられてます。
敵対機構として VIPER (Visual Perturber) という、文字をその文字に似た文字に置き換える機構を提案し、Pos taggingやtoxic comment classificationなどの複数のタスクで 実験したところ、置き換える前より精度が下がった
- 実際に置き換えた文の例

このような置き換えによって精度が下がるのを防ぐ、Shield方法を3つ提案し、実験を行なった。3つの詳細は以下の通り。
- adversarial training: 学習データにVIPERで生成したデータを含める
- character embeddings: 画像情報を利用した単語分散表現を入力に利用
- rule-based recovery: 画像として近い文字にルールベースで置き換え
- → これらの方法で精度の減少は防げるものの、まだ課題は多い
面白いと思った点
- 中国語・韓国語・日本語のような文字レベルのcompositionality (構成性) がある言語とは異なり、ラテン語系は文字レベルで研究を行うことは多くないため、珍しい論文だと思いました
- CVの考え方が、NLPに輸入されることは多いが、モチベーションとして文字レベルのadversarial exampleを生成するという提案は直感的で良い。言語関係なく、表層で単語を認識することは重要だと思います
2. Errudite: Scalable, Reproducible, and Testable Error Analysis
ACL2019
- ACL anthology https://www.aclweb.org/anthology/P19-1073/
- github https://github.com/uwdata/errudite
- website http://idl.cs.washington.edu/papers/errudite/
- blog https://medium.com/@uwdata/errudite-55d5fbf3232e
- 以降の図はblogから引用
NLPに限らず、モデルの特性を理解する上でエラー分析は必須です。 この論文では、エラー分析に関する原則 (principle) を挙げ、それらをインタラクティブにサポートするツール Errudite を紹介しています。
論文では、Machine Comprehension(以下 MC)のモデルBiDAF(Seo et al.,2017)のSQuADデータにおける結果を具体例として用い、原則を記述しています。 ちなみにMCとは、システムに文章を読ませ、理解させるタスクです。また、SQuADは文章と質問を入力とし、質問の回答を文章から選択するタスクのデータセットです。
(参考:文章を読み、理解する機能の獲得に向けて-Machine Comprehensionの研究動向-)
提案されている原則の詳細は以下の3つです。
- エラーの仮説は具体的な描写で正確に定義されるべきである
- e.g. 「質問文が長いと精度が悪い」ではなく「質問文が 20token 以上だと精度が悪い」と書く
- エラーのprevalence(分布率)は全体のデータセットで判断する
BiDAF is good at matching questions to entity types, but is often distracted by other spans with the same entity type(BiDAFは名詞などのエンテティを一致させるのに優れているが、多くの場合、同じエンテティの種類が同じ別の範囲を予測してしまう) という Distractor Hypothesis がある。
- 例えば、上記図のように、ドクターフーの2005年のテーマを作った人物は、Murray Gold が正答だが、同じ種類 (人物) である John Debney と回答してしまう場合のこと
- しかしながら、すべてのinstanceの正答率が68%である一方、その中で、答えがentityであるデータの正答率は80%であることがわかった。
- エラーの仮説は直接的に調べるべきである
- counterfactual questions (反事実的な質問)
“If the predicted distractor was not there, would the model predict correctly?を実証するため、distractorに当たる単語を書き替えてモデルの出力結果が変わるか分析する。
- 上記ドクターフーの例であれば、distractorである John Debney を他の単語( # )に置き換える。すると、モデルの出力はさらに異なる人物名である Ron Grainer と予測した。
- このように、他のdistractorがモデルに誤った予測をさせてしまうケースが29%存在する一方、他の単語( # )に置き換えても予測が変わらないケースが23%存在することがわかった。
- counterfactual questions (反事実的な質問)
面白いと思った点
- エラー分析が意外とおざなりになっていることに注目している点
- appendixをみると、ACLのようなトップ会議に通っている論文でも、エラー分析のサンプルサイズが50程度のケースが存在するがわかります
- 確かに、MCのような文章から答えとなる単語の範囲 (span) を当てるタスクにおいて、どのようにエラー分析すべきかは明文化されてなかったので、個人的に画期的だと思いました
- エラー分析の提案に対して、ツールとして実装し、公開している点
3. Language Models as Knowledge Bases?
EMNLP2019 (to appear)
最初にも述べた、BERTやELMoは言語モデルです。言語モデルとは、尤もらしい文・文章を生成するモデルです。
具体的には、ある文字の並び ] が生成される確率
は
で表されます。
つまり、1からt-1番目まで、] の順番で単語が並んでいる時、その次の単語が
である確率の総乗で表現されます。
(これはシンプルな、一定方向の言語モデルの話です)
本論文では、このような言語モデルが知識ベース (Knowledge Base 以下 KB) としてどの程度扱うことができるか、検証する LAMA (LAnguage Model Analysis) を提案し、実際に検証を行っています。
本来KBは (Dante, born-in, X) のようなスキーマが定まった学習データを用いて X を予測するタスクです。
本論文では、 Dante was born in [Mask] in the year 1265. のように自然文で扱い、[Mask] を予測するタスクとして扱うことで、言語モデルで検証を行なっています。
具体的には、fairseq-fconv, Transformer-XL large, ELMo, BERTといった言語モデルについて、複数のデータセット (Google-RE, T-REx, ConceptNet, SQuAD) を用いて実験を行なっています。
結果として、BERTモデルが、Corpusと予測すべきrelationによっては既存のKBモデルよりも高い精度を達成していることを報告しています。特にT-REx (Wikipediaから抽出されたtripleを予測するタスク) において、1-to-1 relationでMean precision at one (P@1) が74.5という高いパフォーマンスになっています。
面白いと思った点
- 言語モデルでKBを解こうと試みている点
- 大規模コーパスを用いた学習済み言語モデルを用いている以上、既存のKBモデルと単純な比較はできないものの、既存のKBタスクを解くことで学習済み言語モデルが構造的な知識を持っているか調査できる点
余談
- https://talktotransformer.com
- ここでtransformerの出力を試すことができます
- こんな話もあるので、まだまだ検証の余地はあるかもしれません
"Language models as knowledge bases?" they asked: https://t.co/O7BCcy0V6r
— Graham Neubig (@gneubig) September 26, 2019
"A cat has four kidneys", replied GPT-2. pic.twitter.com/yMizwyOSpU
4. A Structural Probe for Finding Syntax in Word Representations
NAACL2019
- ACL anthology https://www.aclweb.org/anthology/papers/N/N19/N19-1419/
- github https://github.com/john-hewitt/structural-probes/
- author site https://nlp.stanford.edu//~johnhew//
- blog https://nlp.stanford.edu//~johnhew/structural-probe.html
- 以降の図はblogから引用
言語モデルの検証を行っている論文をもう一つ紹介します。
この論文では、言語モデルがsyntactic (統語的) な構造を持っているか?を検証する structural probe を提案しています。BERT,ELMoのような言語モデルが出力する単語分散表現を、木構造として扱い、正しくparseできるかどうかを検証します。
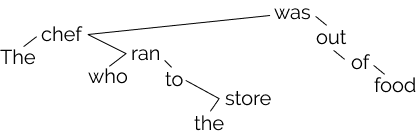
具体的な検証方法は大きく2つです。
ひとつは、2つの単語ベクトルのL2距離の二乗を測るために空間を変換し、短い距離の単語同士をつなげることで構文木を作成する方法。もうひとつは、L2ノルムの二乗で単語の木の深さを測るための線形変換を行い、root (木の根) からの深さを検証する方法です。
Penn Treebankを用いた実験の結果、ELMo・BERTともに変換可能であり、構文木を構築することができることがわかりました。 また、実際の構文木の結果は論文中で可視化されています。
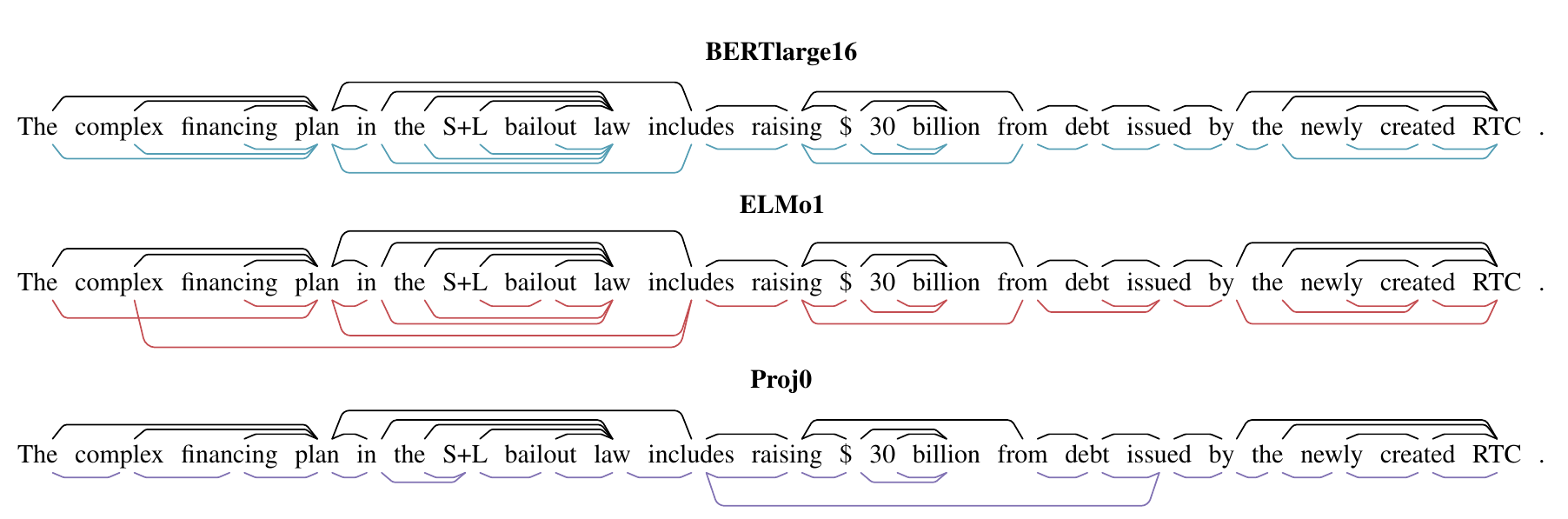
面白いと思った点
- stanfordが言語モデルが統語情報を持っていることを証明するための手法を提案している点
- stanford core NLPなどを公開している、stanfordらしいアプローチだなと思いました
5. Emotion-Cause Pair Extraction: A New Task to Emotion Analysis in Texts
ACL2019
- ACL anthology https://www.aclweb.org/anthology/P19-1096
- arXiv https://arxiv.org/abs/1906.01267
- github https://github.com/NUSTM/ECPE
個人的にsentiment analysisをはじめとした感情分析系に興味があるため、最後にその系統の論文を紹介します。
文書からemotion (感情) とcause (原因) のペアを抽出するタスク emotion-cause pair extraction (ECPE) を新たに提案している論文です。
 From https://medium.com/dair-ai/a-deep-learning-approach-to-improve-emotion-cause-extraction-135bd9ea3899
From https://medium.com/dair-ai/a-deep-learning-approach-to-improve-emotion-cause-extraction-135bd9ea3899
先行研究であるEmotion cause extraction (ECE) はemotionを入力として、causeに該当するclauseを抽出するタスクです。しかし、これだとemotionがアノテーションされている前提のタスクになってしまい、実応用に結びつきません。また、causeとemotionも相互に結びつかないことも問題です。
そこで、emotion-cause pair extraction (ECPE) では、emotionとcauseのどちらも抽出するrelation extraction taskを提案しています。
実際にタスクを解くアプローチとしては、emotion一覧、cause一覧をそれぞれ取得、emotionとcauseのペアにして正解のフィルタリングを行うマルチタスク学習を提案しています。実験を行なった結果としてはemotionの抽出結果をcauseの結果に利用する手法の方がF値が高くなりました。
ちなみに図は英語ですが、論文中で利用しているデータセットは中国語です。
面白いと思った点
- sentiment (ポジネガ) よりも粒度が細かいemotion、そしてその原因も同時に扱う、実応用に近いタスクを提案している点
- より詳細なsentiment analysis (感情分析) を行うaspect-based sentiment analysisやtargeted sentiment analysisと近いが、sentimentをより詳細に扱えるのは面白い。
- 個人的な意見ですが、sentiment、emotionを扱うNLPはレッドオーシャンにも関わらず、実応用として利用されることが多くなっているわけではないため、このようなタスクの精度が上がって実社会で扱えることを期待しています。
おわりに
検証系の論文をメインに紹介しました。
自然言語という人間が何気なく使っているモノに対して、計算機科学を用いて深い理解を得ようとするのがNLPの面白い点です。
また、NLP系の論文では他の研究分野の流れを汲み取ったり (1番目に紹介したAdversarial attack) 、言語の違い (英語・中国語・日本語) によってアプローチに違いがあったり、多角・多様であることも面白い点です。
その面白さが少しでも伝われば幸いです。
")
深層学習による自然言語処理 (機械学習プロフェッショナルシリーズ)
- 作者: 坪井祐太,海野裕也,鈴木潤
- 出版社/メーカー: 講談社
- 発売日: 2017/05/25
- メディア: 単行本(ソフトカバー)
- この商品を含むブログ (1件) を見る